Inference Pool¶
Alpha since v0.1.0
The InferencePool resource is alpha and may have breaking changes in
future releases of the API.
Background¶
The InferencePool resource is a logical grouping of compute resources, e.g. Pods, that run model servers. The InferencePool would deploy its own routing, and offer administrative configuration to the Platform Admin.
It is expected for the InferencePool to:
- Enforce fair consumption of resources across competing workloads
- Efficiently route requests across shared compute (as displayed by the PoC)
It is not expected for the InferencePool to:
- Enforce any common set of adapters or base models are available on the Pods
- Manage Deployments of Pods within the Pool
- Manage Pod lifecycle of pods within the pool
Additionally, any Pod that seeks to join an InferencePool would need to support a protocol, defined by this project, to ensure the Pool has adequate information to intelligently route requests.
InferencePool has some small overlap with Service, displayed here:
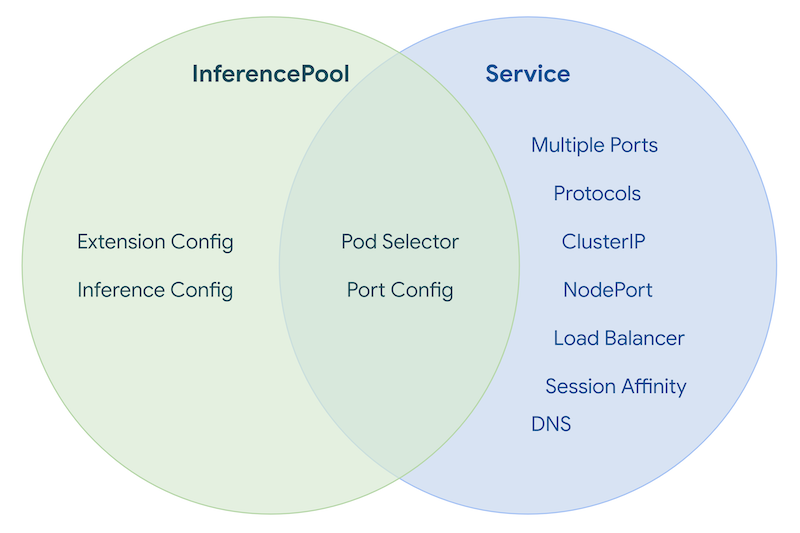
The InferencePool is not intended to be a mask of the Service object, simply exposing the absolute bare minimum required to allow the Platform Admin to focus less on networking, and more on Pool management.
Spec¶
The full spec of the InferencePool is defined here.